

What does indexing mean anyway?
The meaning behind page indexing is based on a big difference between the human visitor of a website and search engines like Google. Already at first glance, the human being recognizes correlations and structures of the page. For him it is immediately obvious that a subpage with the top offers of an online store is more important than the imprint page of the store.
This does not automatically apply to search engines. These must first recognize that a website has sufficient relevance and quality to be included in the search index of Google, Bing & Co. in the first place. If this is the case, the search engine needs help in structuring the page content on a technical level. Only in this way can it really provide users with pages that are relevant in search queries.
Indexing describes the process by which Google and other search engines call up one’s own page and systematically transfer it to the search engine’s index. This is the only way to ensure visibility in search queries. In other words, indexing is the most important basis for further SEO.
Relationship between indexing and crawling
The indexing of websites is done by so-called crawling. For this process, all search engines use automated bots that regularly visit all accessible IP addresses and check whether old or new content can be found there. In the positive case, the crawler delivers the result to the search engine, which decides through algorithms whether the found content should be included in the search engine’s results pages or not.
The process is comparable to the assignment of an index in a library. Here, too, the systematic numbering of all books is common. If new books are added and are suitable for the library, they are also given an index and placed in the correct section of the library. In the case of Google or Bing, the virtual library is merely many billions of web pages in size.
How do I actively perform page indexing?
The process of crawling is automatic. How often a particular web page is crawled depends on the activity on the web page. For example, crawling established news websites several times a day is common to capture breaking news and immediately include it in Google search results. Commercial or private websites with a low rate of change are crawled every few days or weeks.
The same applies to brand new websites. Here, it can take several weeks until the crawler detects and indexes them for the first time. If you don’t want to wait that long with your new website, you can actively intervene in the indexing process – here using Google as an example:
- As the operator of a website, create a Google account.
- Open Google Search Console and create the website as a property of the account owner.
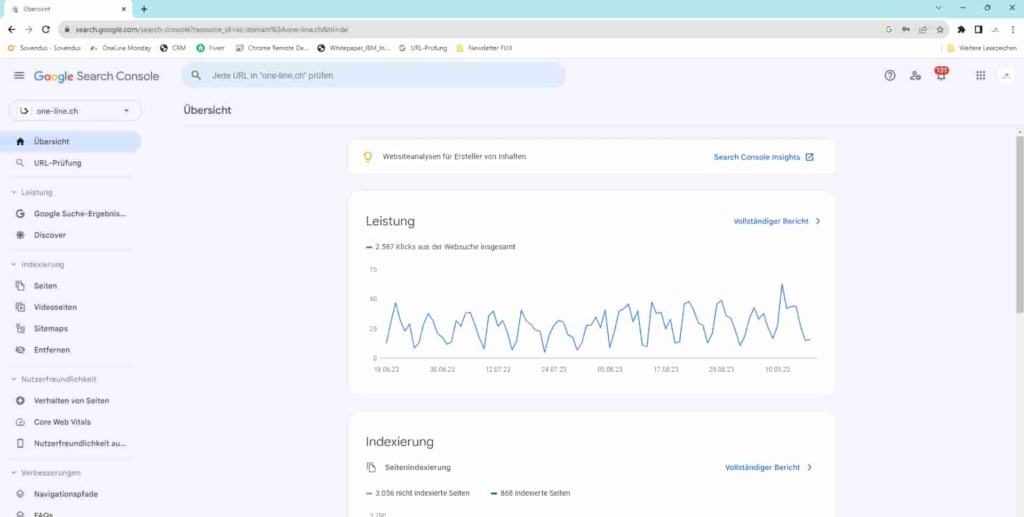
- Now enter the web address of a new page in the Search Console search bar. Google now needs one to two minutes to find and analyze the page.
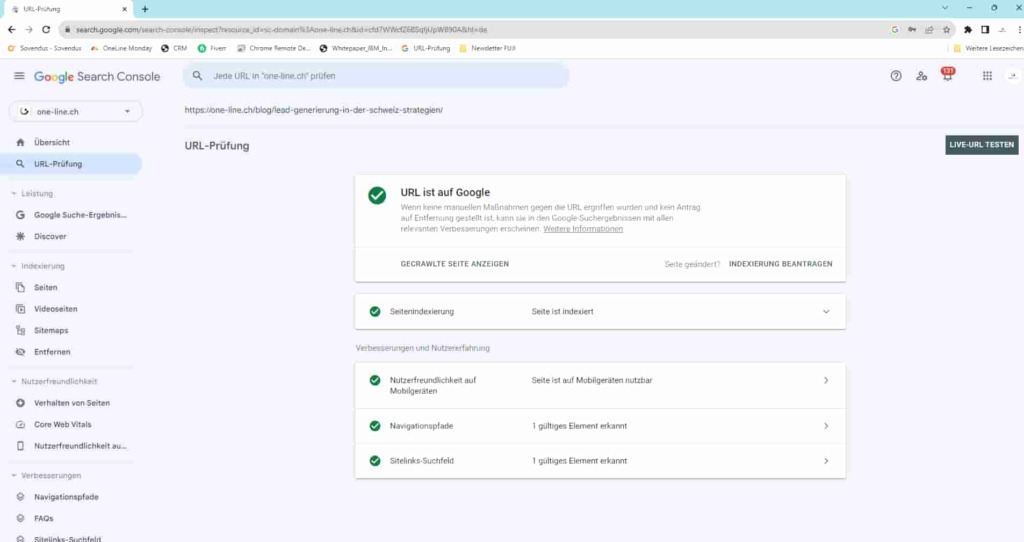
- If it is not yet in the Google search index, you can request inclusion. The process usually takes a few days.
Note that steps 3 and 4 must be performed again for each sub-page that should be found quickly in the Google index. This can be very time-consuming for large websites, especially since you are only allowed to suggest a certain number of pages per day for crawling. Therefore, think carefully about which pages of your new web presence should have the fastest possible visibility.
Does it make sense not to index pages?
At first glance, it seems to make sense to index every web page of your web presence. The logic behind this: The more pages you can offer Google, the more often you should be visible in search queries and increase the site’s traffic. However, this is not the case. There are types of sub-pages that have little added value for human users and do not play a big role even in SEO. Typical pages of this type are:
- Category and keyword pages that serve solely to orient the human user on the page.
- Web pages with imprint, data protection and possibly contact details
- outdated landing pages
- search result pages of an own, on-page search function
All the mentioned page types serve their purpose for the page visitor. However, they are negligible for quality and relevance towards a search engine like Bing or Google. With the tag “noindex”, which can be included in the source code or specified in a content management system, page indexing is deliberately prevented.
Interaction of indexing and SEO
With a systematic and smart indexing users lead an essential contribution for the visibility of the page in search engines as well as for good rankings for relevant search queries. Basically, without indexing you will not be found in the “library” of Google or Bing and any further SEO measure can not bring success.
Conversely, indexing itself does not yet result in successful SEO with top rankings. Rather, you must now ensure quality and relevance of the page content. For this, for example, unique texts with added value and high-quality media elements are important. If, for example, you fill the category pages of a store with the same texts over and over again, Google will see only one of these texts as canonical. The result: one of these pages ends up in the Google search index, the others are no longer listed. Uniqueness and quality are therefore important so that every relevant subpage earns its page indexing.
Develop a coherent overall concept for SEO
Whether automatically by a bot or by an active triggering via the Google Search Console – the one-time indexing of a high-quality website is sufficient to appear permanently in the search results. A regular check of the indexed pages is nevertheless worthwhile, which can be done systematically via the Google Search Console. ONELINE helps you with this and shows which professional measures in online marketing and page optimization are also worthwhile.


